CausalML - Analysing AB Test Results

Introduction
In this blog I’ll take you through the analysis of A/B test results using CausalML package. It is an easy and powerful package for causal inference that takes into account propensity matching, conditional probabilities and much more. Here, I’ll use a dataset with ingrained bias to show how you can still estimate the treatment effect without extensive pre-processing and exploratory analysis. You can download the data here and get full code in my github repo. Thanks to this repo for initial data.
Experiments in Marketing
Experiments are a staple of causal reasoning and are widely used in many disciplines. In digital marketing, A/B test refers to the experiment design that splits the user base into two groups - control and treatment. Treatment group gets exposed to a new feature/design/offer/etc. while the control group’s experience stays the same. The behaviours of two groups are monitored and compared with regards to a specific metric (e.g. conversion rate). If the treatment group has a statistically better performance, then the experiment is considered a success and the feature gets rolled out to the entire user base.
Let’s imagine a scenario: we want to know whether serving a website with localised translations is better than our current version of one-size-fits-all approach. We decide to run an A/B test and track the conversions of two groups. We will analyse the data that we’ve gathered so far to see the effect of our proposed change.
Data Preprocessing
This dataset is split into two tables, which we’ll need to join. Also, most of the variables need to be transformed to serve as inputs into the ML model of choice (here it’s LightGBM). To get the data ready, we’ll do the following pre-processing steps:
- Get seasonal variables from date
- Join two dataset
- Drop Spain because it has no localised translation
- Transform categorical into numerical
#Imports
#Data processing
import pandas as pd
import numpy as np
#Uplift Modelling
from lightgbm import LGBMClassifier
from sklearn.model_selection import cross_val_score
from causalml.inference.meta import BaseXClassifier
from sklearn.linear_model import LinearRegression
#Visualisations
import seaborn as sns
import matplotlib.pyplot as plt
main = pd.read_csv('./data/test_table.csv')
users = pd.read_csv('./data/user_table.csv')
#PREPROCESSING
#Adding seasonal variables
main['date'] = pd.to_datetime(main.date, format = '%Y-%m-%d')
main['month'] = main['date'].apply(lambda x: x.month)
main['day_month'] = main['date'].apply(lambda x: x.day)
#Dropping date column
main = main.drop('date', axis=1)
#Joining user data
main = main.merge(users, how='inner')
#Drop Spain country
main = main.loc[main['country'] != 'Spain', :]
#Transforming to numerical
main['ads_channel'] = main['ads_channel'].fillna('direct')
categorical = ['source', 'device', 'browser_language', 'ads_channel', 'browser', 'sex', 'country']
for c in categorical:
main[c] = LabelEncoder().fit_transform(main[c])
main[c] = main[c].astype('category')
Here’s how the resulting data should look like:
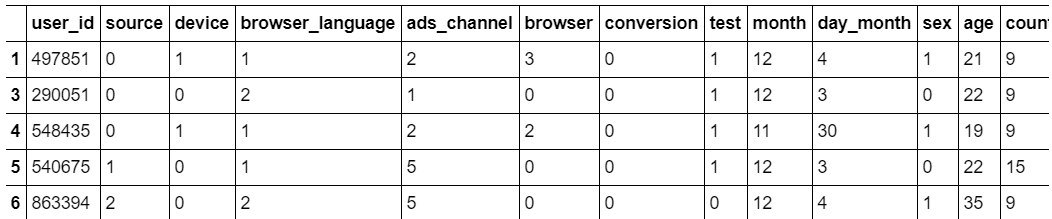
Initial Analysis
Columns in the dataframe above are:
- Test - 1 if a person is part of a test group, 0 if a user is part of control group
- Conversion - our outcome variable
- Everything else is context for a particular conversion (potential confounders)
If the experiment was properly set-up, we’d be able to directly compare the conversion rates of two groups, and conclude if the experiment was a success.
sns.set_style("whitegrid")
sns.barplot(x = ['Control', 'Treatment'], y = main.groupby('test')['conversion'].mean().values)
plt.title('Conversion Rate')
plt.show()
print(f'Difference between Control and Treatment {np.round(main.groupby("test")["conversion"].mean()[1] - main.groupby("test")["conversion"].mean()[0], 5)}')
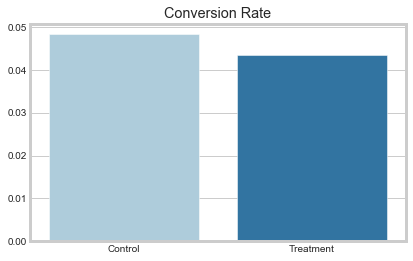
From this it follows that the conversion rate is smaller by 0.4% in treatment group. However, upon taking a closer look at the data, you might begin to notice some irrelugarities. For example, by grouping the data by Country and Test columns you’ll see that countries with indices 0 and 14 have much more Treatment observations than Control. This might be an indication of selection bias, so we can’t compare two means directly. Luckily, CausalML helps us to identify this type of inconsistencies and gives us a more unbiased result.
CausalML - X Learner
CausalML is a Python package that provides access to a suite of algorithms dedicated to uplift modelling and causal inference. It has a range of meta-learner algorithms (meaning that they can take any ML model as base) that estimate Average Treatment Effect (ATE) and Conditional Average Treatment Effect (CATE). In this blog I’ll focus on estimating ATE because this is what the A/B Testing is all about, but I’ll definitely cover the CATE estimation later. CausalML so far has 4 meta-algorithms - S-Learner, T-Learner, X-Learner, R-Learner. Here I’ll be using X-Learner because it is one of the most recent developments in causal inference, and because it excels with imbalanced data (like in our case). The algorithm works in 3 stages:
- Train 2 ML models - the first is for users who have converted, and the second one is for users who haven’t
- Based on the difference between the observed outcome and predicted outcome (using the reverse outcome models) train another 2 ML models
- Run the observations through the final two models and get a weighted average of CATE using the propensity scores as weights
I know that I’ve skimmed through the methodology part, but the official documentation and the actual paper by Künzel et al. (2019) explain the methodology quite nicely, so make sure to read it.
CausalML - Data Prep
There are a few steps prior to modelling with CausalML:
- Separate variables into Treatment, Outcome, and Confounders
- Get Propensity Scores
#Treatment
treatment = main['test']
treatment = np.array(['treatment' if val==1 else 'control' for val in treatment])
pd.Series(treatment).value_counts()
#Outcome
y = main['conversion']
y.value_counts()
#Confounders
X = main.drop(['user_id', 'conversion', 'test'], axis=1)
Note: propensity scoring can be done automatically in the package (by not providing the propensity scores) but I thought that it would be nice to cover to understand the algorithms a bit better.
Propensity model is build by treating the Treatment variable as dependent, and Confounders as independent variables. If we achieve a model with AUC score larger than 0.5 (random guessing), we can say that we have some sort of a sampling bias.
#Propensity Model
prop_model = LGBMClassifier(colsample_bytree=0.8, subsample = 0.8, n_estimators=300)
print(cross_val_score(prop_model, X, treatment, cv=5, scoring='roc_auc').mean())
#model achieves AUC of 0.57, which makes it useful in evaluating the test outcome
#Fitting the model
prop_model.fit(X, treatment)
#Getting propensity scores
prop_scores = prop_model.predict_proba(X)
X-Learner ATE Estimation
Now that the data is ready and propensity scores are estimated, the actual ATE estimation takes only a few seconds. Key things to remember here:
- Choose the right class of meta-learner depending on your task - Regressor or Classifier
- learner parameter has to be consistent with your meta-learner class
- If you use Classifier meta-learner, you also need to provide efffect learners which are regressors
#Fitting the X-meta learner
learner_x = BaseXClassifier(learner = LGBMClassifier(colsample_bytree=0.8, num_leaves=50, n_estimators=200
control_effect_learner=LinearRegression(),
treatment_effect_learner=LinearRegression(),
control_name='control')
#Getting the average treatment effect with upper and lower bounds
ate_x, ate_x_lb, ate_x_ub = learner_x.estimate_ate(X=X, treatment=treatment, y=y, p = prop_scores[:, 1])
print(ate_x, ate_x_lb, ate_x_ub)
The output should be that the average effect of our change is about 0.0. This means that there is no clear effect of our experiment on the propensity to convert which is in contrast to our previous conclusion.
Summary
Overall, our initial conclusion that the change has negative effect was wrong. We were able to get a more unbiased estimate of treatment effect using X meta-learner from CausalML package. Let me know your thoughts and if you want me to cover any other topics in testing and causal inference.